返回主页
返回专栏页
人工智能对抗安全子平台的框架:Benchmarking Adversarial Robustness on Image Classification
本项目针对对抗鲁棒的评估问题,创新性地提出了AI攻防“动态平衡”机制,旨在为算法模型提供安全性测评和攻击防御加固方案。该平台支持了不同图像分类任务数据集,支持了不同威胁模型下的、不同距离度量下的、不同攻击目标下的典型对抗攻击算法,提供了易用的模型接口,提供了典型防御方法的预训练模型,旨在为评估对抗攻防方法和模型鲁棒性提供方便统一的平台。基于该平台,我们进行了大规模全面系统的实验以合理评估攻击算法的性能和防御模型的鲁棒性:我们选定模型准确率与攻击成功率随攻击强度变化的曲线、模型准确率与攻击成功率随扰动大小变化的曲线作为指标,评测了多个典型防御模型在多种典型威胁模型的攻击算法下的对抗鲁棒性,通过分析定量的实验结果,我们有一些发现。
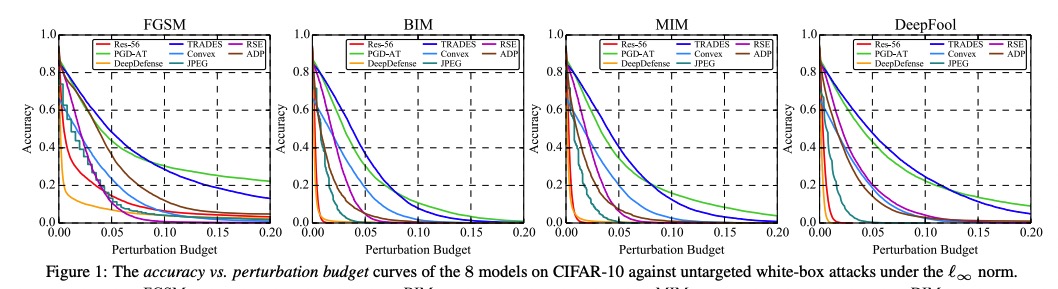
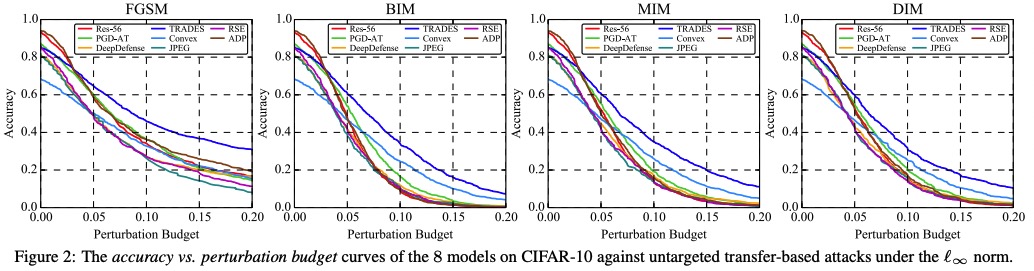
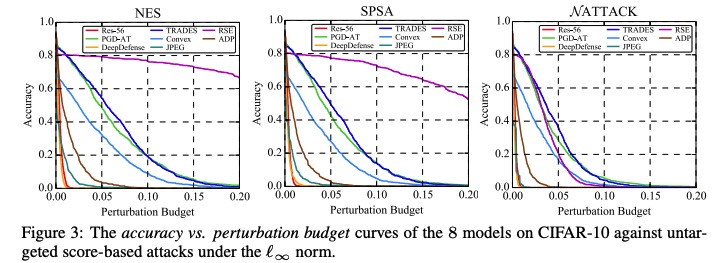
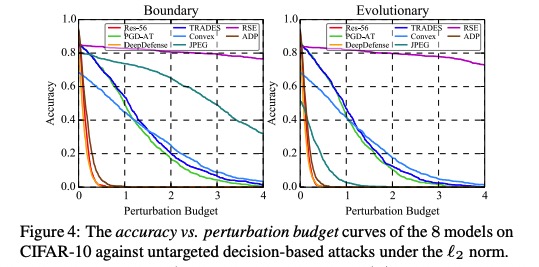
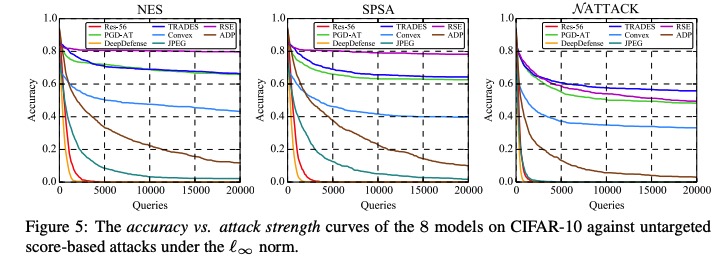
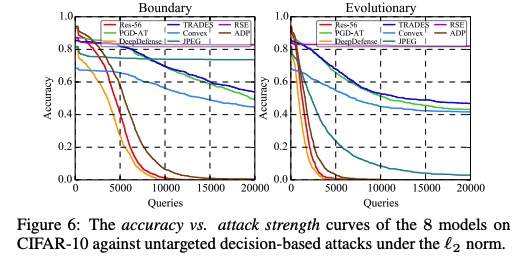 部分白盒和黑盒攻击实验结果图
部分白盒和黑盒攻击实验结果图
该成果在计算机视觉领域重要学术会议CVPR2020发表。
论文引用:Dong Y.; Fu Q.-A.; Yang X.; Pang T.; Su H.*; Xiao Z.; Zhu J.; Benchmarking adversarial robustness on image classification, 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, Washington, 2020-6-14至2020-6-19.